| ration | weight_gain |
|---|---|
| A | 31 |
| A | 34 |
| A | 29 |
| A | 26 |
| A | 32 |
| A | 35 |
| A | 38 |
| A | 34 |
| A | 31 |
| A | 29 |
| A | 32 |
| A | 31 |
| B | 26 |
| B | 24 |
| B | 28 |
| B | 29 |
| B | 30 |
| B | 29 |
| B | 31 |
| B | 29 |
| B | 32 |
| B | 26 |
| B | 28 |
| B | 32 |
24 The Statistics of Hypothesis-Testing With Measured Data
Chapter 21 and Chapter 19 discussed testing a hypothesis with data that either arrive in dichotomized (yes-no) form, or come as data in situations where it is convenient to dichotomize. We next consider hypothesis testing using measured data. Conventional statistical practice employs such devices as the “t-test” and “analysis of variance.” In contrast to those complex devices, the resampling method does not differ greatly from what has been discussed in previous chapters.
24.0.1 Example: The Pig Rations Still Once Again, Using Measured Data
Testing for the difference between means of two equal-sized samples of measured-data observations
Let us now treat the pig-food problem without converting the quantitative data into qualitative data, because a conversion always loses information.
The term “lose information” can be understood intuitively. Consider two sets of three sacks of corn. Set A includes sacks containing, respectively, one pound, two pounds, and three pounds. Set B includes sacks of one pound, two pounds, and a hundred pounds. If we rank the sacks by weight, the two sets can no longer be distinguished. The one-pound and two-pound sacks have ranks one and two in both cases, and their relative places in their sets are the same. But if we know not only that the one-pound sack is the smallest of its set and the three-pound or hundred-pound sack is the largest, but also that the largest sack is three pounds (or a hundred pounds), we have more information about a set than if we only know the ranks of its sacks.
Rank data are also known as “ordinal” data, whereas data measured in (say) pounds are known as “cardinal” data. Even though converting from cardinal (measured) to ordinal (ranked) data loses information, the conversion may increase convenience, and may therefore be worth doing in some cases.
Table 24.1 has the measured data for pig rations A and B.
We begin a measured-data procedure by noting that if the two pig foods are the same, then each of the observed weight gains came from the same benchmark universe. This is the basic tactic in our statistical strategy. That is, if the two foods came from the same universe, our best guess about the composition of that universe is that it includes weight gains just like the twenty-four we have observed, and in the same proportions, because that is all the information that we have about the universe; this is the bootstrap method. Since ours is (by definition) a sample from an infinite (or at least, a very large) universe of possible weight gains, we assume that there are many weight gains in the universe just like the ones we have observed, in the same proportion as we have observed them. For example, we assume that 2/24 of the universe is composed of 34-pound weight gains, as seen in Figure 24.1:
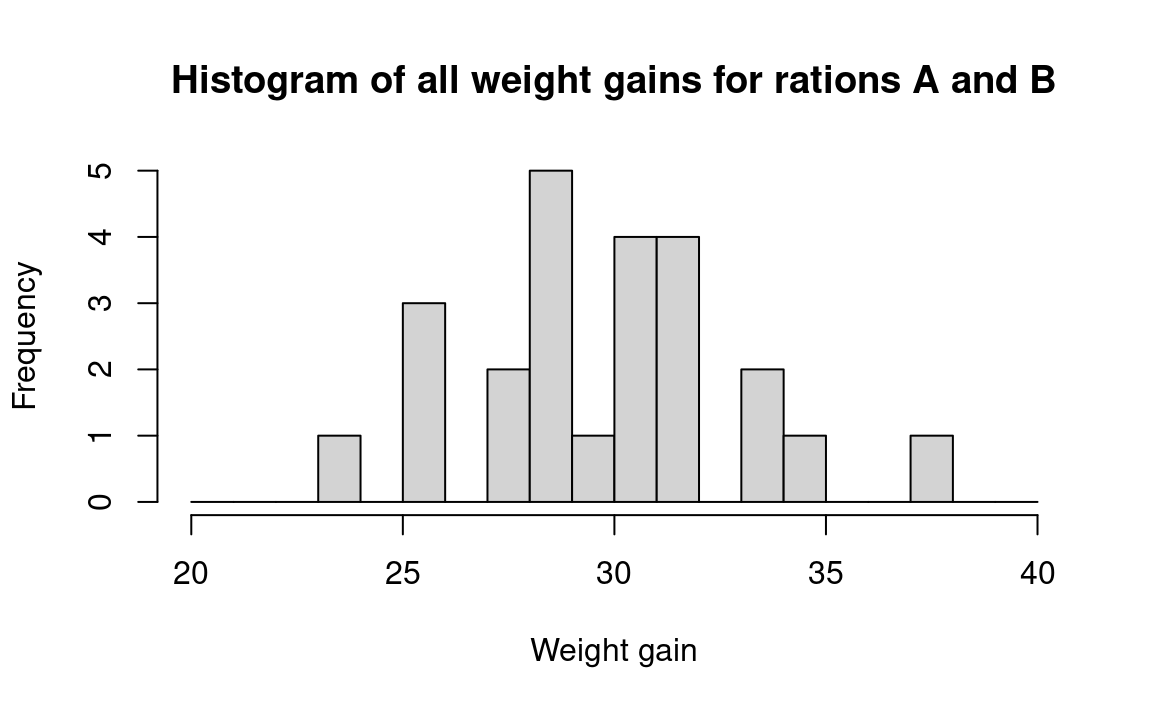
We recognize, of course, that weight gains other than the exact ones we observed certainly would occur in repeated experiments. And if we thought it reasonable to do so, we could assume that the “distribution” of the weight gains would follow a regular “smooth” shape such as Figure 24.2. But deciding just how to draw Figure 24.2 from the data in Figure 24.1 requires that we make arbitrary assumptions about unknown conditions. And if we were to draw Figure 24.2 in a form that would be sufficiently regular for conventional mathematical analysis, we might have to make some very strong assumptions going far beyond the observed data.
Drawing a smooth curve such as Figure 24.2 from the raw data in Figure 24.1 might be satisfactory — if done with wisdom and good judgment. But there is no necessity to draw such a smooth curve, in this case or in most cases. We can proceed by assuming simply that the benchmark universe — the universe to which we shall compare our samples, conventionally called the “null” or “hypothetical” universe — is composed only of elements similar to the observations we have in hand. We thereby lose no efficiency and avoid making unsound assumptions.
To carry out our procedure in practice: 1) Write down each of the twenty-four weight gains on a blank index card. We then have one card each for 31, 34, 29, 26, and so on. 2) Shuffle the twenty-four cards thoroughly, and pick one card. 3) Record the weight gain, and replace the card. (Recall that we are treating the weight gains as if they come from an infinite universe — that is, as if the probability of selecting any amount is the same no matter which others are selected randomly. Another way to say this is to state that each selection is independent of each other selection. If we did not replace the card before selecting the next weight gain, the selections would no longer be independent. See Chapter 11 for further discussion of this issue.) 4) Repeat this process until you have made two sets of 12 observations. 5) Call the first hand “food A” and the second hand “food B.” Determine the average weight gain for the two hands, and record it as in Table 24.2. Repeat this procedure many times.
In operational steps:
- Step 1. Write down each observed weight gain on a card, e.g. 31, 34, 29 …
- Step 2. Shuffle and deal a card.
- Step 3. Record the weight and replace the card.
- Step 4. Repeat steps 2 and 3 eleven more times; call this group A.
- Step 5. Repeat steps 2-3 another twelve times; call this group B.
- Step 6. Calculate the mean weight gain of each group.
- Step 7. Subtract the mean of group A from the mean of group B and record. If larger (more positive) than 3.16 (the difference between the observed means) or more negative than -3.16, record “more.” Otherwise record “less.”
- Step 8. Repeat this procedure perhaps fifty times, and calculate the proportion “more.” This estimates the probability sought.
In none of the first ten simulated trials did the difference in the means of the random hands exceed the observed difference (3.16 pounds, in the top line in the table) between foods A and B. (The difference between group totals tells the same story and is faster, requiring no division calculations.)
In the old days before a computer was easily available, I (JLS) would quit making trials at such a point, confident that a difference in means as great as observed is not likely to happen by chance. (Using the convenient “multiplication rule” described in Chapter 9, we can estimate the probability of such an occurrence happening by chance in 10 successive trials as \(\frac{1}{2} * \frac{1}{2} * \frac{1}{2} ... = \frac{1}{2}^{10} = 1/1024 \approx .001\) = .1 percent, a small chance indeed.) Nevertheless, let us press on to do 50 trials.
| Trial # | Mean of first 12 observations (first hand) | Mean of second 12 observations (second hand) | Difference | Greater or less than observed difference? | |||
|---|---|---|---|---|---|---|---|
| Observed | 382 / 12=31.83 | ||||||
| 1 | 368 / 12=30.67 | 357 / 12=29.75 | .87 | Less | |||
| 2 | 364 / 12=30.33 | 361 / 12=30.08 | .25 | Less | |||
| 3 | 352 / 12=29.33 | 373 / 12=31.08 | (1.75) | Less | |||
| 4 | 378 / 12=31.50 | 347 / 12=28.92 | 2.58 | Less | |||
| 5 | 365 / 12=30.42 | 360 / 12=30.00 | .42 | Less | |||
| 6 | 352 / 12=29.33 | 373 / 12=31.08 | (1.75) | Less | |||
| 7 | 355 / 12=29.58 | 370 / 12=30.83 | (1.25) | Less | |||
| 8 | 366 / 12=30.50 | 359 / 12=29.92 | .58 | Less | |||
| 9 | 360 / 12=30.00 | 365 / 12=30.42 | (.42) | Less | |||
| 10 | 355 / 12=29.58 | 370 / 12=30.83 | (1.25) | Less | |||
| 11 | 359 / 12=29.92 | 366 / 12=30.50 | (.58) | Less | |||
| 12 | 369 / 12=30.75 | 356 / 12=29.67 | 1.08 | ” | |||
| 13 | 360 / 12=30.00 | 365 / 12=30.42 | (.42) | Less | |||
| 14 | 377 / 12=31.42 | 348 / 12=29.00 | 2.42 | Less | |||
| 15 | 365 / 12=30.42 | 360 / 12=30.00 | .42 | Less | |||
| 16 | 364 / 12=30.33 | 361 / 12=30.08 | .25 | Less | |||
| 17 | 363 / 12=30.25 | 362 / 12=30.17 | .08 | Less | |||
| 18 | 365 / 12=30.42 | 360 / 12=30.00 | .42 | Less | |||
| 19 | 369 / 12=30.75 | 356 / 12=29.67 | 1.08 | Less | |||
| 20 | 369 / 12=30.75 | 356 / 12=29.67 | 1.08 | Less | |||
| 21 | 369 / 12=30.75 | 356 / 12=29.67 | 1.08 | Less | |||
| 22 | 364 / 12=30.33 | 361 / 12=30.08 | .25 | Less | |||
| 23 | 363 / 12=30.25 | 362 / 12=30.17 | .08 | Less | |||
| 24 | 363 / 12=30.25 | 362 / 12=30.17 | .08 | Less | |||
| 25 | 364 / 12=30.33 | 361 / 12=30.08 | .25 | Less | |||
| 26 | 359 / 12=29.92 | 366 / 12=30.50 | (.58) | Less | |||
| 27 | 362 / 12=30.17 | 363 / 12=30.25 | (.08) | Less | |||
| 28 | 362 / 12=30.17 | 363 / 12=30.25 | (.08) | Less | |||
| 29 | 373 / 12=31.08 | 352 / 12=29.33 | 1.75 | Less | |||
| 30 | 367 / 12=30.58 | 358 / 12=29.83 | .75 | Less | |||
| 31 | 376 / 12=31.33 | 349 / 12=29.08 | 2.25 | Less | |||
| 32 | 365 / 12=30.42 | 360 / 12=30.00 | .42 | Less | |||
| 33 | 357 / 12=29.75 | 368 / 12=30.67 | (1.42) | Less | |||
| 34 | 349 / 12=29.08 | 376 / 12=31.33 | 2.25 | Less | |||
| 35 | 356 / 12=29.67 | 396 / 12=30.75 | (1.08) | Less | |||
| 36 | 359 / 12=29.92 | 366 / 12=30.50 | (.58) | Less | |||
| 37 | 372 / 12=31.00 | 353 / 12=29.42 | 1.58 | Less | |||
| 38 | 368 / 12=30.67 | 357 / 12=29.75 | .92 | Less | |||
| 39 | 344 / 12=28.67 | 382 / 12=31.81 | (3.16) | Equal | |||
| 40 | 365 / 12=30.42 | 360 / 12=30.00 | .42 | Less | |||
| 41 | 375 / 12=31.25 | 350 / 12=29.17 | 2.08 | Less | |||
| 42 | 353 / 12=29.42 | 372 / 12=31.00 | (1.58) | Less | |||
| 43 | 357 / 12=29.75 | 368 / 12=30.67 | (.92) | Less | |||
| 44 | 363 / 12=30.25 | 362 / 12=30.17 | .08 | Less | |||
| 45 | 353 / 12=29.42 | 372 / 12=31.00 | (1.58) | Less | |||
| 46 | 354 / 12=29.50 | 371 / 12=30.92 | (1.42) | Less | |||
| 47 | 353 / 12=29.42 | 372 / 12=31.00 | (1.58) | Less | |||
| 48 | 366 / 12=30.50 | 350 / 12=29.92 | .58 | Less | |||
| 49 | 364 / 12=30.53 | 361 / 12=30.08 | .25 | Less | |||
| 50 | 370 / 12=30.83 | 355 / 12=29.58 | 1.25 | Less | |||
Table 24.2 shows fifty trials of which only one (the thirty-ninth) is as “far out” as the observed samples. These data give us an estimate of the probability that, if the two foods come from the same universe, a difference this great or greater would occur just by chance. (Compare this 2 percent estimate with the probability of roughly 1 percent estimated with the conventional t test — a “significance level” of 1 percent.) On the average, the test described in this section yields a significance level as high as such mathematical-probability tests as the t test — that is, it is just as efficient — though the tests described in the examples of Section 21.2.8 and Section 23.3.1 are likely to be less efficient because they convert measured data to ranked or classified data.1
It is not appropriate to say that these data give us an estimate of the probability that the foods “do not come” from the same universe. This is because we can never state a probability that a sample came from a given universe unless the alternatives are fully specified in advance.2
This example also illustrates how the dispersion within samples affects the difficulty of finding out whether the samples differ from each other. For example, the average weight gain for food A was 32 pounds, versus 29 pounds for food B. If all the food A-fed pigs had gained weight within a range of say 29.9 and 30.1 pounds, and if all the food B-fed pigs had gained weight within a range of 28.9 and 29.1 pounds — that is, if the highest weight gain in food B had been lower than the lowest weight gain in food A — then there would be no question that food A is better, and even fewer observations would have made this statistically conclusive. Variation (dispersion) is thus of great importance in statistics and in the social sciences. The larger the dispersion among the observations within the samples, the larger the sample size necessary to make a conclusive comparison between two groups or reliable estimates of summarization statistics. (The dispersion might be measured by the mean absolute deviation (the average absolute difference between the mean and the individual observations, treating both plus and minus differences as positive), the variance (the average squared difference between the mean and the observations), the standard deviation (the square root of the variance), the range (the difference between the smallest and largest observations), or some other device.)
If you are performing your tests by hand rather than using a computer (a good exercise even nowadays when computers are so accessible), you might prefer to work with the median instead of the mean, because the median requires less computation. (The median also has the advantage of being less influenced by a single far-out observation that might be quite atypical; all measures have their special advantages and disadvantages.) Simply compare the difference in medians of the twelve-pig resamples to the difference in medians of the actual samples, just as was done with the means. The only operational difference is to substitute the word “median” for the word “mean” in the steps listed above. You may need a somewhat larger number of trials when working with medians, however, for they tend to be less precise than means.
The R notebook compares the difference in the sums of the weight gains for the actual pigs against the difference resulting from two randomly-chosen groups of pigs, using the same numerical weight gains of individual pigs as were obtained in the actual experiment. If the differences in average weight gains of the randomly ordered groups are rarely as large as the difference in weight gains from the actual sets of pigs fed food A-alpha and food B-beta, then we can conclude that the foods do make a difference in pigs’ weight gains.
Note first that pigs in group A gained a total of 382 pounds while group B gained a total of 344 pounds — 38 fewer. To minimize computations, we will deal with totals like these, not averages.
First we construct vectors A and B of the weight gains of the pigs fed with the two foods. Then we combine the two vectors into one long vector and select two groups of 12 randomly and with replacement (the two sample commands). Notice we sample with replacement. This is the bootstrap procedure*, where we simulate new samples by resampling with replacement from the original sample. We sum the weight gains for the two resamples, and calculate the difference. We keep track of those differences by storing them in the results array, graph them on a histogram, and see how many times resample A exceeded resample B by at least 38 pounds, or vice versa (we are testing whether the two are different, not whether food A produces larger weight gains).
Notebook with data file
As you saw in Note 16.1, the following notebook reads a data file, so the download link points to a .zip file containing the notebook and the data file.
Note 24.1: Notebook: Pig rations via bootstrap
First we need to get the measured data from the data file using R:
We load the file containing the data:
# Read the data file containing pig ration data.
rations_df <- read.csv('data/pig_rations.csv')
# Show the first 6 rows.
head(rations_df) ration weight_gain
1 A 31
2 A 34
3 A 29
4 A 26
5 A 32
6 A 35Let us first select the rows containing data for ration B (we will get the rows for ration A afterwards):
# Select ration B rows.
ration_b_df <- subset(rations_df, rations_df['ration'] == 'B')
# Show the first six rows.
head(ration_b_df) ration weight_gain
13 B 26
14 B 24
15 B 28
16 B 29
17 B 30
18 B 29Finally for ration B, convert the weights to a vector for use in the simulation.
b_weights <- ration_b_df$weight_gain
# Show the result.
b_weights [1] 26 24 28 29 30 29 31 29 32 26 28 32Select ration A rows, and get the weights as a vector:
ration_a_df <- subset(rations_df, rations_df['ration'] == 'A')
a_weights <- ration_a_df$weight_gain
# Show the result.
a_weights [1] 31 34 29 26 32 35 38 34 31 29 32 31We will use the a_weights and b_weights vectors for our simulation. We are going to shuffle these weights, so we first concatenate the two vectors (see Section 12.16.1) so we can shuffle them:
both <- c(a_weights, b_weights)
both [1] 31 34 29 26 32 35 38 34 31 29 32 31 26 24 28 29 30 29 31 29 32 26 28 32Now do the simulation:
# Set the number of trials
n_trials <- 10000
# An empty array to store the trial results.
results <- numeric(n_trials)
# Do 10,000 experiments.
for (i in 1:n_trials) {
# Take a "resample" of 12 with replacement from both and put it in fake_a
fake_a <- sample(both, size=12, replace=TRUE)
# Likewise to make fake_b
fake_b <- sample(both, size=12, replace=TRUE)
# Sum the first "resample."
fake_a_sum <- sum(fake_a)
# Sum the second "resample."
fake_b_sum <- sum(fake_b)
# Calculate the difference between the two resamples.
fake_diff <- fake_a_sum - fake_b_sum
# Keep track of each trial result.
results[i] <- fake_diff
# End one experiment, go back and repeat until all trials are complete,
# then proceed.
}
# Produce a histogram of trial results.
hist(results, breaks=25,
xlab='Second resample minus first',
main='Distribution difference in sums of resamples')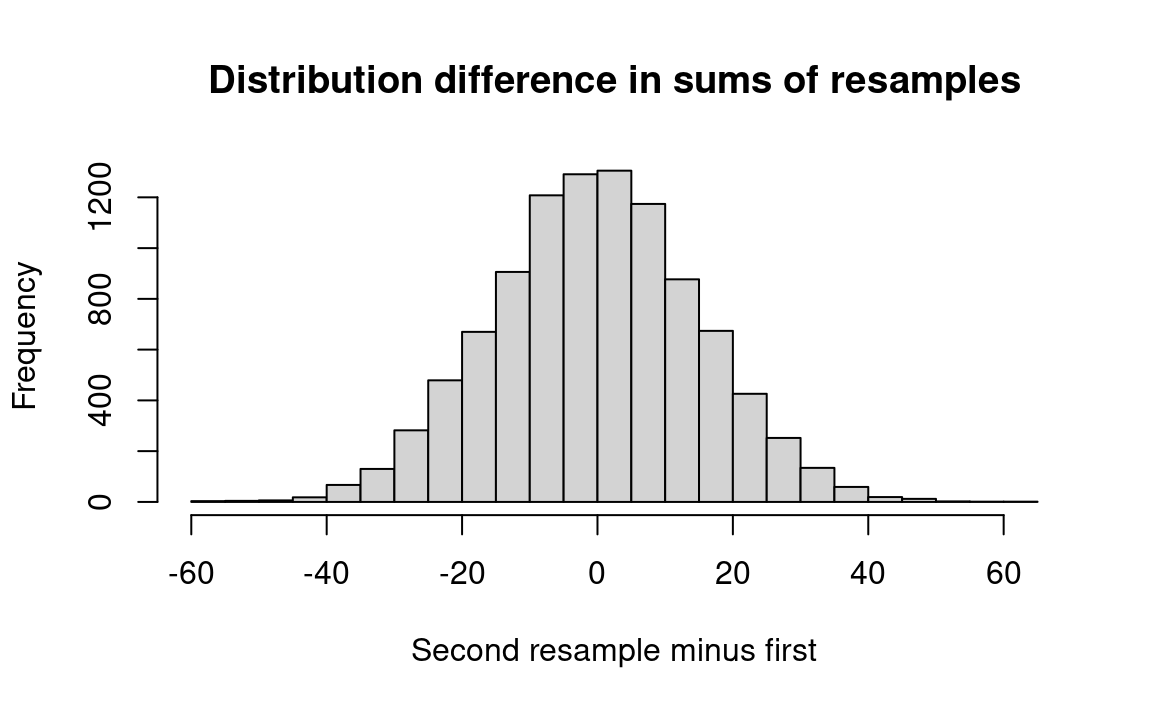
From this histogram we see that a very small proportion of the trials produced a difference between groups as large as that observed (or larger). R will calculate this for us with the following code:
# Determine how many of the trials produced a difference between resamples.
count_more <- sum(results >= 38)
# Likewise for a difference of -38.
count_less <- sum(results <= -38)
# Add the two together.
k = count_more + count_less
# Divide by number of trials to convert to proportion.
kk = k / n_trials
# Print the result.
message('Proportion of trials with either >=38 or <=-38: ', kk)Proportion of trials with either >=38 or <=-38: 0.012
End of notebook: Pig rations via bootstrap
measured_rations starts at Note 24.1.
24.0.2 Example: Is There a Difference in Liquor Prices Between State-Run and Privately-Run Systems?
This is an example of testing for differences between means of unequal-sized samples of measured data.
In the 1960s I (JLS) studied the price of liquor in the sixteen “monopoly” states (where the state government owns the retail liquor stores) compared to the twenty-six states in which retail liquor stores are privately owned. (Some states were omitted for technical reasons. And it is interesting to note that the situation and the price pattern has changed radically since then.) These data were introduced in the context of a problem in probability in Section 12.16.
Table 24.3 is the same as the matching table in Section 12.16. They show the representative 1961 prices of a fifth of Seagram 7 Crown whiskey in the two sets of states:3
| Private | Government | |
|---|---|---|
| 4.82 | 4.65 | |
| 5.29 | 4.55 | |
| 4.89 | 4.11 | |
| 4.95 | 4.15 | |
| 4.55 | 4.2 | |
| 4.9 | 4.55 | |
| 5.25 | 3.8 | |
| 5.3 | 4.0 | |
| 4.29 | 4.19 | |
| 4.85 | 4.75 | |
| 4.54 | 4.74 | |
| 4.75 | 4.5 | |
| 4.85 | 4.1 | |
| 4.85 | 4.0 | |
| 4.5 | 5.05 | |
| 4.75 | 4.2 | |
| 4.79 | ||
| 4.85 | ||
| 4.79 | ||
| 4.95 | ||
| 4.95 | ||
| 4.75 | ||
| 5.2 | ||
| 5.1 | ||
| 4.8 | ||
| 4.29 | ||
| Count | 26 | 16 |
| Mean | 4.84 | 4.35 |
The economic question that underlay the investigation — having both theoretical and policy ramifications — is as follows: Does state ownership affect prices? The empirical question is whether the prices in the two sets of states were systematically different. In statistical terms, we wish to test the hypothesis that there was a difference between the groups of states related to their mode of liquor distribution, or whether the observed $.49 differential in means might well have occurred by happenstance. In other words, we want to know whether the two sub-groups of states differed systematically in their liquor prices, or whether the observed pattern could well have been produced by chance variability.
The first step is to examine the two sets of data graphically to see whether there was such a clear-cut difference between them — of the order of Snow’s data on cholera, or the Japanese Navy data on beri-beri — that no test was necessary. The separate displays, and then the two combined together, are shown in Figure 24.3; the answer is not clear-cut and hence a formal test is necessary.
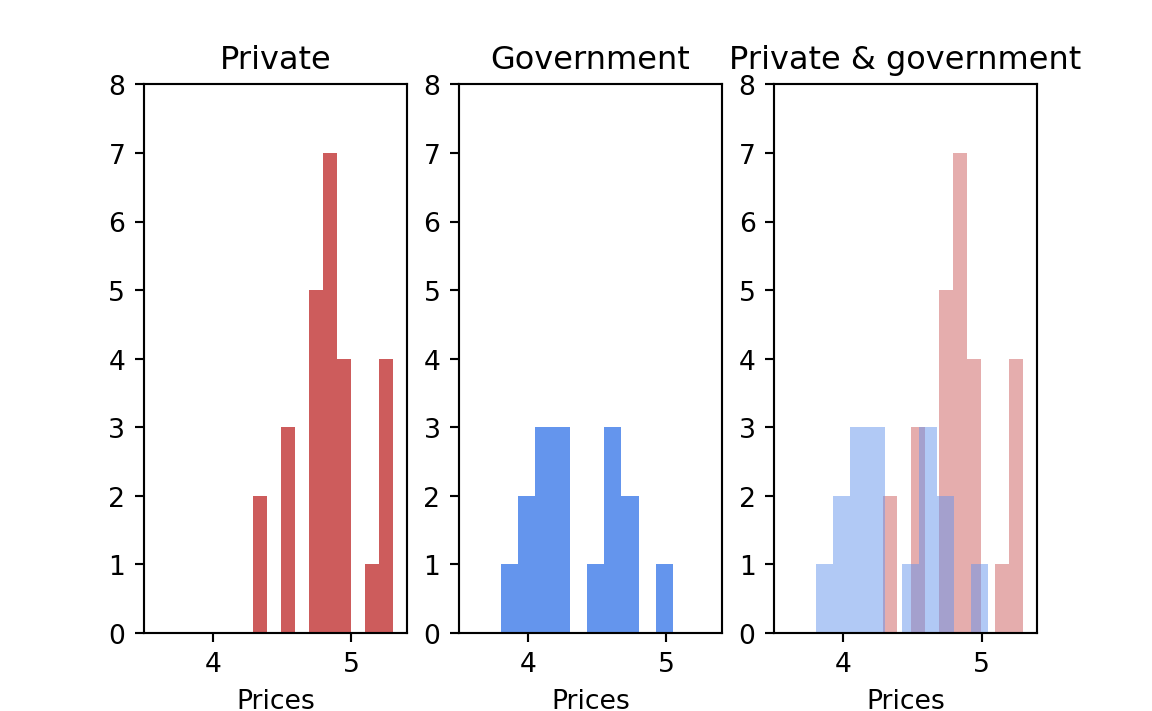
At first I used a resampling permutation test as follows: Assuming that the entire universe of possible prices consists of the set of events that were observed, because that is all the information available about the universe, I wrote each of the forty-two observed state prices on a separate card. The shuffled deck simulated a situation in which each state has an equal chance for each price.
On the “null hypothesis” that the two groups’ prices do not reflect different price-setting mechanisms, but rather differ only by chance, I then examined how often that simulated universe stochastically produces groups with results as different as observed in 1961. I repeatedly dealt groups of 16 and 26 cards, without replacing the cards, to simulate hypothetical monopoly-state and private-state samples, each time calculating the difference in mean prices.
The probability that the benchmark null-hypothesis universe would produce a difference between groups as large or larger than observed in 1961 is estimated by how frequently the mean of the group of randomly-chosen sixteen prices from the simulated state-ownership universe is less than (or equal to) the mean of the actual sixteen state-ownership prices. If the simulated difference between the randomly-chosen groups was frequently equal to or greater than observed in 1961, one would not conclude that the observed difference was due to the type of retailing system because it could well have been due to chance variation.
Here is that procedure as an R notebook. Compare to the very similar bootstrap procedure in Section 12.16.
Note 24.2: Notebook: Permutation test of public and private liquor prices
# Load the data from a data file.
prices_df <- read.csv('data/liquor_prices.csv')
# Show this first six rows.
head(prices_df) state_type price
1 private 4.82
2 private 5.29
3 private 4.89
4 private 4.95
5 private 4.55
6 private 4.90Take all prices from the loaded data file, and convert into a vectors for each category.
# Rows for private prices.
priv_df <- subset(prices_df, prices_df['state_type'] == 'private')
# Convert corresponding prices to vector.
priv <- priv_df$price
# Show the result.
priv [1] 4.82 5.29 4.89 4.95 4.55 4.90 5.25 5.30 4.29 4.85 4.54 4.75 4.85 4.85 4.50
[16] 4.75 4.79 4.85 4.79 4.95 4.95 4.75 5.20 5.10 4.80 4.29# Rows for government prices.
govt_df <- subset(prices_df, prices_df['state_type'] == 'government')
# Convert corresponding prices to vector.
govt = govt_df$price
# Show the result.
govt [1] 4.65 4.55 4.11 4.15 4.20 4.55 3.80 4.00 4.19 4.75 4.74 4.50 4.10 4.00 5.05
[16] 4.20Calculate actual difference:
actual_diff <- mean(priv) - mean(govt)
actual_diff[1] 0.492Concatenate the private and government values into one vector:
# Join the two vectors of data into one vector.
both <- c(priv, govt)
both [1] 4.82 5.29 4.89 4.95 4.55 4.90 5.25 5.30 4.29 4.85 4.54 4.75 4.85 4.85 4.50
[16] 4.75 4.79 4.85 4.79 4.95 4.95 4.75 5.20 5.10 4.80 4.29 4.65 4.55 4.11 4.15
[31] 4.20 4.55 3.80 4.00 4.19 4.75 4.74 4.50 4.10 4.00 5.05 4.20Do simulation:
n_trials <- 10000
# Fake differences for each trial.
results <- numeric(n_trials)
# Repeat 10000 simulation trials
for (i in 1:10000) {
# Shuffle 42 values to a random order.
shuffled = sample(both)
# Take first 26 shuffled values as fake private group
fake_priv = shuffled[1:26]
# Remaining values (from position 27 to end, 16 values)
# form the fake government group.
fake_govt = shuffled[27:42]
# Find the mean of the "private" group.
p <- mean(fake_priv)
# Mean of the "govt." group
g <- mean(fake_govt)
# Difference in the means
diff <- p - g
# Keep score of the trials
results[i] <- diff
}
# Graph of simulation results to compare with the observed result.
fig_title <- paste('Average price difference (Actual difference = ',
round(actual_diff * 100),
'cents')
hist(results, main=fig_title, xlab='Difference in average prices (cents)')
# Number of trials where fake difference >= actual.
k = sum(results >= actual_diff)
kk = k / n_trials
message('Proportion fake differences <= actual_difference: ', kk)Proportion fake differences <= actual_difference: 0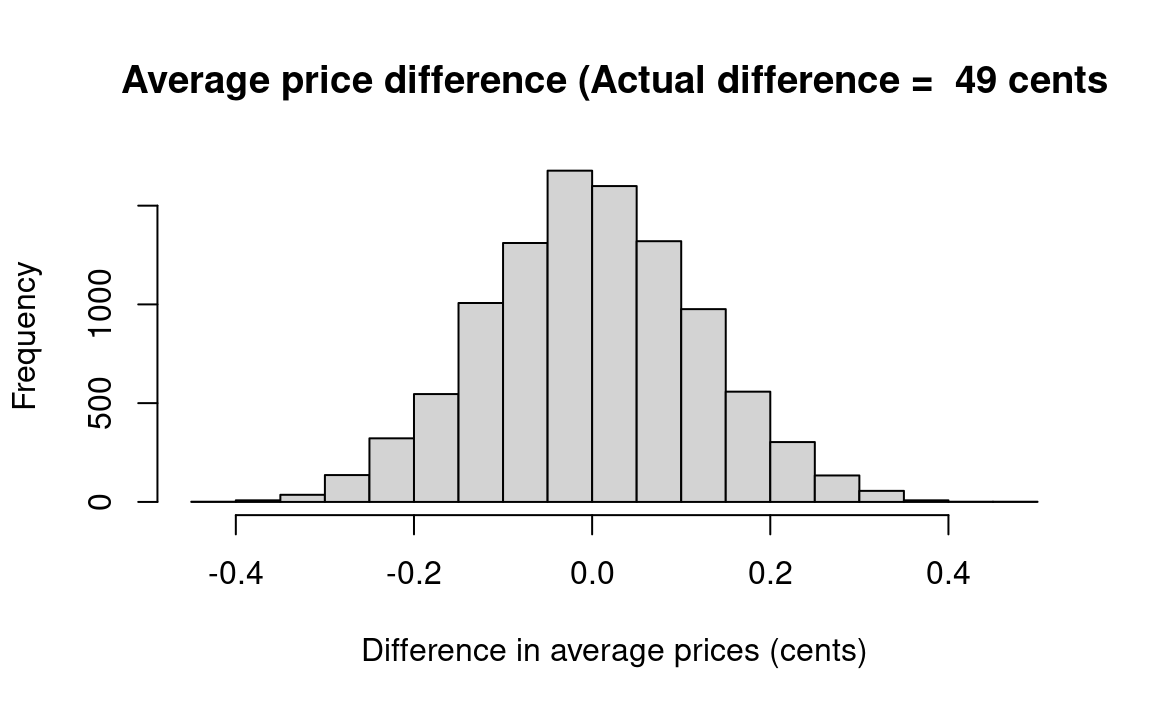
End of notebook: Permutation test of public and private liquor prices
liquor_permutation starts at Note 24.2.
The result — about zero percent of the simulations generated a value as large or larger than the actual difference — implies that there is a very small probability that two groups with mean prices as different as were observed would happen by chance if drawn from the universe of 42 observed prices. So we “reject the null hypothesis” and instead find persuasive the proposition that the type of liquor distribution system influences the prices that consumers pay.4
The logical framework of this resampling version of the permutation test differs greatly from the formulaic version, which relies on some sophisticated mathematics. The formula-method alternative would be the Student’s t-test, in which the user simply plugs into an unintuitive formula and reads the result from a table.
A R program to handle the liquor problem with an infinite-universe bootstrap distribution simply substitutes the random sampling command sample for the commands to do shuffling and splitting above. The results of the bootstrap test are indistinguishable from those in the permutation version of the program above — see: Section 12.16.
Still another difficult question is whether any hypothesis test is appropriate, because the states were not randomly selected for inclusion in one group or another, and the results could be caused by factors other than the liquor system; this applies to both the above methods. The states constitute the entire universe in which we are interested, rather than being a sample taken from some larger universe as with a biological experiment or a small survey sample. But this objection pertains to a conventional test as well as to resampling methods. And a similar question arises throughout medical and social science — to the two water suppliers between which John Snow detected vast differences in cholera rates, to rates of lung cancer in human smokers, to analyses of changes in speeding laws, and so on.
The appropriate question is not whether the units were assigned randomly, however, but whether there is strong reason to believe that the results are not meaningful because they are the result of a particular “hidden” variable.
These debates about fundamentals illustrate the unsettled state of statistical thinking about basic issues. Other disciplines also have their controversies about fundamentals. But in statistics these issues arise as early as the introductory course, because all but the most contrived problems are shot through with these questions. Instructors and researchers usually gloss over these matters, as Gigerenzer et al., show ( The Empire of Chance ). Again, because with resampling one does not become immersed in the difficult mathematical techniques that underlie conventional methods, one is quicker to see these difficult questions, which apply equally to conventional methods and resampling.
24.0.3 Example: Is there a difference between treatments to prevent low birthweights?
Next we consider the use of resampling with measured data to test the hypothesis that drug A prevents low birthweights (Rosner 1995, 291). The data for the treatment and control groups are shown in Table 24.4.
| Treatment | Birthweight |
|---|---|
| Drug A | 6.9 |
| Drug A | 7.6 |
| Drug A | 7.3 |
| Drug A | 7.6 |
| Drug A | 6.8 |
| Drug A | 7.2 |
| Drug A | 8.0 |
| Drug A | 5.5 |
| Drug A | 5.8 |
| Drug A | 7.3 |
| Drug A | 8.2 |
| Drug A | 6.9 |
| Drug A | 6.8 |
| Drug A | 5.7 |
| Drug A | 8.6 |
| Control | 6.4 |
| Control | 6.7 |
| Control | 5.4 |
| Control | 8.2 |
| Control | 5.3 |
| Control | 6.6 |
| Control | 5.8 |
| Control | 5.7 |
| Control | 6.2 |
| Control | 7.1 |
| Control | 7.0 |
| Control | 6.9 |
| Control | 5.6 |
| Control | 4.2 |
| Control | 6.8 |
The treatment group averaged .82 pounds more than the control group (Table 24.5):
| Mean birthweight | |
|---|---|
| Control | 6.26 |
| Drug A | 7.08 |
Here is a resampling approach to the problem:
- If the drug has no effect, our best guess about the “universe” of birthweights is that it is composed of (say) a million each of the observed weights, all lumped together. In other words, in the absence of any other information or compelling theory, we assume that the combination of our samples is our best estimate of the universe. Hence let us write each of the birthweights on a card, and put them into a hat. Drawing them one by one and then replacing them is the operational equivalent of a very large (but equal) number of each birthweight.
- Repeatedly draw two samples of 15 birthweights each, and check how frequently the observed difference is as large as, or larger than, the actual difference of .82 pounds.
This is the so-called bootstrap test of the null-hypothesis.
Note 24.3: Notebook: Bootstrap test of birthweight difference
Proceed with the simulation:
# Get treatment and control values from data file.
birth_df <- read.csv('data/birthweights.csv')
# Birthweidhts for Drug A participants.
treat_df <- subset(birth_df, birth_df$Treatment == 'Drug A')
# Birthweigts as vector.
treat <- treat_df$Birthweight
# Control birthweights.
control_df <- subset(birth_df, birth_df$Treatment == 'Control')
# Birthweigts as vector.
control <- control_df$Birthweight
# Actual difference.
actual_diff <- mean(treat) - mean(control)
# Show the actual difference.
actual_diff[1] 0.82Proceed with the simulation:
# Concatenate treatment and control vectors.
both <- c(treat, control)
# Number of trials.
n_trials <- 10000
# Make vector to store results for each trial.
results <- numeric(n_trials)
# Do 10000 simulations
for (i in 1:n_trials) {
# Take a resample of 15 from all birth weights.
fake_treat <- sample(both, size=15, replace=TRUE)
# Take a second, similar resample.
fake_control <- sample(both, size=15, replace=TRUE)
# Find the means of the two resamples.
mt <- mean(fake_treat)
mc <- mean(fake_control)
# Find the difference between the means of the two resamples.
diff <- mt - mc
# Keep score of the result.
results[i] <- diff
# End the simulation experiment, go back and repeat
}
# Produce a histogram of the resample differences
hist(results, breaks=25,
main='Null-world distribution of treatment/control difference',
xlab='Null-world mean treatment - mean control')
# How often did resample differences exceed the observed difference of
# .82?
k <- sum(results >= actual_diff)
kk <- k / n_trials
message('Proportion null-world differences >= actual difference: ', kk)Proportion null-world differences >= actual difference: 0.0109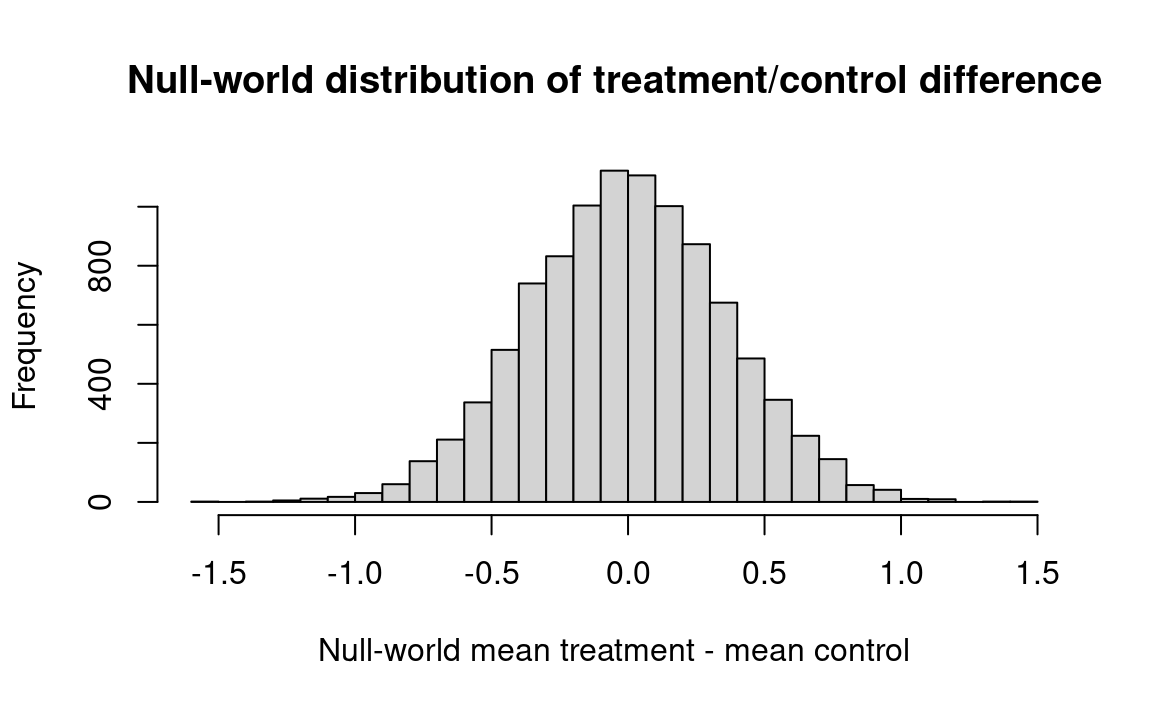
End of notebook: Bootstrap test of birthweight difference
birthweight_bootstap starts at Note 24.3.
Result: only about one percent of the pairs of resamples produced means that differed by as much as .82. We can conclude that the observed difference is unlikely to have occurred by chance.
24.0.4 Example: Bootstrap Sampling with Replacement
Efron and Tibshirani (1993, 11) present this as their basic problem illustrating the bootstrap method: Seven mice were given a new medical treatment intended to improve their survival rates after surgery, and nine mice were not treated. The numbers of days the treated mice survived were 94, 38, 23, 197, 99, 16 and 14, whereas the numbers of days the untreated mice (the control group) survived were 52, 10, 40, 104, 51, 27, 146, 30, and 46. The question we ask is: Did the treatment prolong survival, or might chance variation be responsible for the observed difference in mean survival times?
We start by supposing the treatment did NOT prolong survival and that chance variation in the mice was responsible for the observed difference.
If that is so, then we consider that the two groups came from the same universe. Now we’d like to know how likely it is that two groups drawn from this common universe would differ as much as the two observed groups differ.
If we had unlimited time and money, we would seek additional samples in the same way that we obtained these. Lacking time and money, we create a hypothetical universe that embodies everything we know about such a common universe. We imagine replicating each sample element millions of times to create an almost infinite universe that looks just like our samples. Then we can take resamples from this hypothetical universe and see how they behave.
Even on a computer, creating such a large universe is tedious so we use a shortcut. We replace each element after we pick it for a resample. That way, our hypothetical (bootstrap) universe is effectively infinite.
The following procedure will serve:
- Step 1. Calculate the difference between the means of the two observed samples – it’s 30.63 days in favor of the treated mice.
- Step 2. Consider the two samples combined (16 observations) as the relevant universe to resample from.
- Step 3. Draw 7 hypothetical observations with replacement and designate them “Treatment”; draw 9 hypothetical observations with replacement and designate them “Control.”
- Step 4. Compute and record the difference between the means of the two samples. ** Step 5.** Repeat steps 2 and 3 perhaps 10000 times. ** Step 6.** Determine how often the resampled difference exceeds the observed difference of 30.63.
The following notebook follows the above procedure:
Note 24.4: Notebook: A classic bootstrap example
# Treatment group.
treat <- c(94, 38, 23, 197, 99, 16, 141)
# control group
control <- c(52, 10, 40, 104, 51, 27, 146, 30, 46)
# Observed difference in real world.
actual_diff <- mean(treat) - mean(control)
# Set the number of trials.
n_trials <- 10000
# An empty array to store the trials.
results <- numeric(n_trials)
# U is our universe (Step 2 above)
u <- c(treat, control)
# step 5 above.
for (i in 1:n_trials) {
# Step 3 above.
fake_treat <- sample(u, size=7, replace=TRUE)
# Step 3.
fake_control <- sample(u, size=9, replace=TRUE)
# Step 4.
mt <- mean(fake_treat)
# Step 4.
mc <- mean(fake_control)
# Step 4.
diff <- mt - mc
# Step 4.
results[i] <- diff
}
# Step 6
hist(results, breaks=25,
main='Bootstrap distribution of mean differences in survival',
xlab='Bootstrap mean treatment - mean control')
# Step 6
k <- sum(results >= actual_diff)
kk <- k / n_trials
message('Proportion bootstrap mean difference >= actual difference: ', kk)Proportion bootstrap mean difference >= actual difference: 0.1272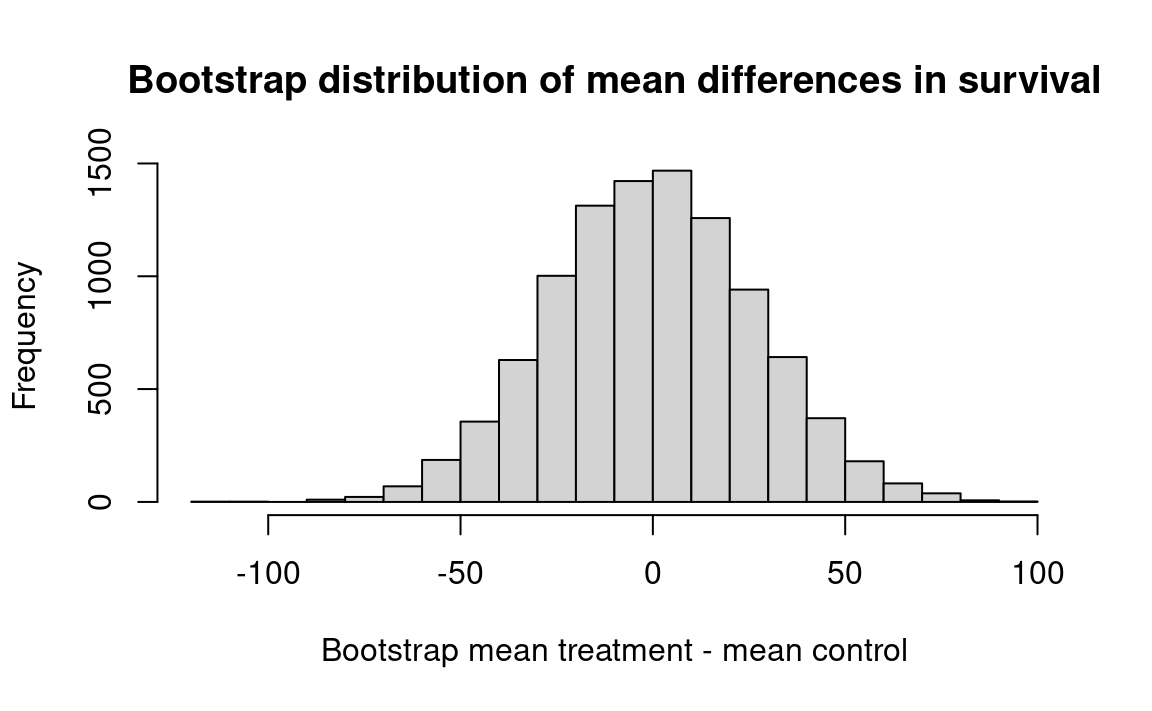
End of notebook: A classic bootstrap example
mouse_bootstrap starts at Note 24.4.
Interpretation: 10000 simulated resamples (of sizes 7 and 9) from a combined universe produced a difference as big as 30.63 about 12.7 percent of the time. We cannot rule out the possibility that chance might be responsible for the observed advantage of the treatment group.
24.0.5 Example: Permutation Sampling Without Replacement
This section discusses at some length the question of when sampling with replacement (the bootstrap), and sampling without replacement (permutation or “exact” test) are the appropriate resampling methods. The case at hand seems like a clearcut case where the bootstrap is appropriate. (Note that in this case we draw both samples from a combined universe consisting of all observations, whether we do so with or without replacement.) Nevertheless, let us see how the technique would differ if one were to consider that the permutation test is appropriate. The algorithm would then be as follows (with the steps that are the same as above labeled “a” and those that are different labeled “b”):
- Step 1a. Calculate the difference between the means of the two observed samples – it’s 30.63 days in favor of the treated mice.
- Step 2a. Consider the two samples combined (16 observations) as the relevant universe to resample from.
- Step 3b. Draw 7 hypothetical observations without replacement and designate them “Treatment”; draw the remaining 9 hypothetical observations and designate them “Control.” (We can do this by shuffling our universe and splitting it into groups by taking the first 7 and the last 9.)
- Step 4a. Compute and record the difference between the means of the two samples.
- Step 5a. Repeat steps 2 and 3 perhaps 10,000 times
- Step 6a. Determine how often the resampled difference exceeds the observed difference of 30.63.
Here is the R notebook:
Note 24.5: Notebook: Permutation test for mouse survival data
# Treatment group.
treat <- c(94, 38, 23, 197, 99, 16, 141)
# control group
control <- c(52, 10, 40, 104, 51, 27, 146, 30, 46)
# Observed difference in real world.
actual_diff <- mean(treat) - mean(control)
# Set the number of trials.
n_trials <- 10000
# An empty array to store the trials.
results <- numeric(n_trials)
# U is our universe (Step 2 above)
u <- c(treat, control)
# step 5 above.
for (i in 1:n_trials) {
# Step 3b above.
shuffled <- sample(u)
# Step 3b - take the first 7 values.
fake_treat <- shuffled[1:7]
# Step 3b - take the remaining values.
fake_control <- shuffled[8:16]
# Step 4.
mt <- mean(fake_treat)
# Step 4.
mc <- mean(fake_control)
# Step 4.
diff <- mt - mc
# Step 4.
results[i] <- diff
}
# Step 6
hist(results, breaks=25,
main='Permutation distribution of mean differences in survival',
xlab='Permutation mean treatment - mean control')
# Step 6
k <- sum(results >= actual_diff)
kk <- k / n_trials
message('Proportion permutation mean difference >= actual difference: ', kk)Proportion permutation mean difference >= actual difference: 0.1406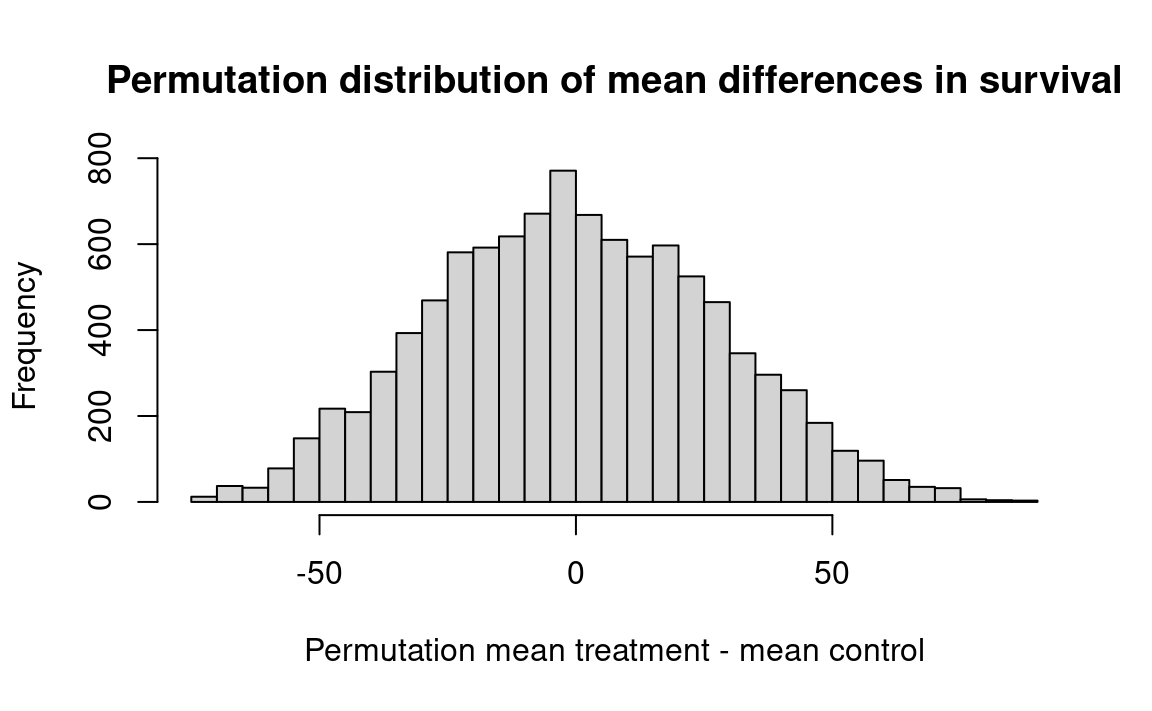
End of notebook: Permutation test for mouse survival data
mouse_permutation starts at Note 24.5.
Interpretation: 10000 simulated resamples (of sizes 7 and 9) from a combined universe produced a difference as big as 30.63 about 14.1 percent of the time. We therefore should not rule out the possibility that chance might be responsible for the observed advantage of the treatment group.
24.1 Differences among four means
24.1.1 Example: differences among four pig rations
Test for Differences Among Means of More Than Two Samples of Measured Data.
In the examples of Section 21.2.1 and Section 21.2.2 we investigated whether or not the results shown by a single sample are sufficiently different from a null (benchmark) hypothesis so that the sample is unlikely to have come from the null-hypothesis benchmark universe. In the examples of Section 21.2.5, Section 23.3.1, and Section 24.0.1 we then investigated whether or not the results shown by two samples suggest that both had come from the same universe, a universe that was assumed to be the composite of the two samples. Now, as in Section 23.2.1, we investigate whether or not several samples come from the same universe, except that now we work with measured data rather than with counted data.
If one experiments with each of 100 different pig foods on twelve pigs, some of the foods will show much better results than will others just by chance, just as one family in sixteen is likely to have the very “high” number of 4 daughters in its first four children. Therefore, it is wrong reasoning to try out the 100 pig foods, select the food that shows the best results, and then compare it statistically with the average (sum) of all the other foods (or worse, with the poorest food). With such a procedure and enough samples, you will surely find one (or more) that seems very atypical statistically. A bridge hand with 12 or 13 spades seems very atypical, too, but if you deal enough bridge hands you will sooner or later get one with 12 or 13 spades — as a purely chance phenomenon, dealt randomly from a standard deck. Therefore we need a test that prevents our falling into such traps. Such a test usually operates by taking into account the differences among all the foods that were tried.
The method of Section 24.0.1 can be extended to handle this problem. Assume that four foods were each tested on twelve pigs. The weight gains in pounds for the pigs fed on foods A and B were as before. Table 24.6 has the weight gains for foods C and D. (Compare these with the weight gains for foods A and B in Table 24.1).
| ration | weight_gain | |
|---|---|---|
| 25 | C | 30 |
| 26 | C | 30 |
| 27 | C | 32 |
| 28 | C | 31 |
| 29 | C | 29 |
| 30 | C | 27 |
| 31 | C | 25 |
| 32 | C | 30 |
| 33 | C | 31 |
| 34 | C | 32 |
| 35 | C | 34 |
| 36 | C | 33 |
| 37 | D | 32 |
| 38 | D | 25 |
| 39 | D | 31 |
| 40 | D | 26 |
| 41 | D | 32 |
| 42 | D | 27 |
| 43 | D | 28 |
| 44 | D | 29 |
| 45 | D | 29 |
| 46 | D | 28 |
| 47 | D | 23 |
| 48 | D | 25 |
Now construct a benchmark universe of forty-eight index cards, one for each weight gain. Then deal out sets of four hands randomly. More specifically:
- Step 1. Constitute a universe of the forty-eight observed weight gains in the four samples, writing the weight gains on cards.
- Step 2. Draw four groups of twelve weight gains, with replacement, since we are drawing from a hypothesized infinite universe in which consecutive draws are independent. Determine whether the difference between the lowest and highest group means is as large or larger than the observed difference. If so write “yes,” otherwise “no.”
- Step 3. Repeat step 2 fifty times.
- Step 4. Count the trials in which the differences between the simulated groups with the highest and lowest means are as large or larger than the differences between the means of the highest and lowest observed samples. The proportion of such trials to the total number of trials is the probability that all four samples would differ as much as do the observed samples if they (in technical terms) come from the same universe.
The problem, as handled by the steps given above, is quite similar to the way we handled the example in Section 23.2.2, except that the data are measured (in pounds of weight gain) rather than simply counted (the number of rehabilitations).
Instead of working through a program for the procedure outlined above, let us consider a different approach to the problem — computing the difference between each pair of foods, six differences in all, converting all minus (-) signs to (+) differences (taking the absolute value). Then we can total the six absolute differences, and compare the total with the sum of the six absolute differences in the observed sample. The proportion of the resampling trials in which the observed sample sum is equaled or exceeded by the sum of the differences in the trials is the probability that the observed samples would differ as much as they do if they come from the same universe.5
One naturally wonders whether this latter test statistic is better than the range, as discussed above. It would seem obvious that using the information contained in all four samples should increase the precision of the estimate. And indeed it is so, as you can confirm for yourself by comparing the results of the two approaches. But in the long run, the estimate provided by the two approaches would be much the same. That is, there is no reason to think that one or another of the estimates is biased. However, successive samples from the population would steady down faster to the true value using the four-group-based estimate than they would using the range. That is, the four-group-based estimate would require a smaller sample of pigs.
Is there reason to prefer one or the other approach from the point of view of some decision that might be made? One might think that the range procedure throws light on which one of the foods is best in a way that the four-group-based approach does not. But this is not correct. Both approaches answer this question, and only this question: Are the results from the four foods likely to have resulted from the same “universe” of weight gains or not? If one wants to know whether the best food is similar to, say, all the other three, the appropriate approach would be a two-sample approach similar to various two-sample examples discussed earlier. (It would be still another question to ask whether the best food is different from the worst. One would then use a procedure different from either of those discussed above.)
If the foods cost the same, one would not need even a two-sample analysis to decide which food to feed. Feed the one whose results are best in the experiment, without bothering to ask whether it is “really” the best; you can’t go wrong as long as it doesn’t cost more to use it. (One could inquire about the probability that the food yielding the best results in the experiment would attain those results by chance even if it was worse than the others by some stipulated amount, but pursuing that line of thought may be left to the student as an exercise.)
In the notebook below, we want a measure of how the groups differ. The obvious first step is to add up the total weight gains for each group (Table 24.7):
| Sum of weight gains | |
|---|---|
| A | 382 |
| B | 344 |
| C | 364 |
| D | 335 |
The next step is to calculate the differences between all the possible combinations of groups.
differences <- c(382 - 344, 382 - 364, 382 - 335,
344 - 364, 344 - 335, 364 - 335)
differences[1] 38 18 47 -20 9 2924.2 Using Squared Differences
Here we face a choice. We could work with the absolute differences — that is, the results of the subtractions — treating each result as a positive number even if it is negative. We have seen this approach before. Therefore let us now take the opportunity of showing another approach. Instead of working with the absolute differences, we square each difference, and then sum the squares.
Squaring vectors squares each element of the vector (see Section 16.7.1):
squared_differences <- differences ** 2
squared_differences[1] 1444 324 2209 400 81 841sum_sq_d = sum(squared_differences)
sum_sq_d[1] 5299An advantage of working with the squares is that they are positive — a negative number squared is positive — which is convenient. Additionally, conventional statistics works mainly with squared quantities, and therefore it is worth getting familiar with that point of view. The squared differences in this case add up to 5299.
Using R, we shuffle all the weight gains together, select four random groups, and determine whether the sum of squared differences in the resample equal or exceed 5299. If they do so with regularity, then we conclude that the observed differences could easily have occurred by chance.
With the c func, we string the four vectors into a single vector called all_weights. After shuffling (using sample the 48-pig weight-gain vector all_weights into shuffled, we split shuffled into four randomized samples. And we compute the squared differences between the pairs of groups and sum the squared differences just as we did above for the observed groups.
Last, we examine how often the simulated-trials data produce differences among the groups as large as (or larger than) the actually observed data — 5299.
Note 24.6: Notebook: Sum of squared differences for pig rations
# Load data file.
rations_df <- read.csv('data/pig_rations.csv')
# Show the first six rows.
head(rations_df) ration weight_gain
1 A 31
2 A 34
3 A 29
4 A 26
5 A 32
6 A 35# Get vectors for each ration.
# A
a_rows <- subset(rations_df, rations_df$ration == 'A')
a_weights <- a_rows$weight_gain
# B
b_rows <- subset(rations_df, rations_df$ration == 'B')
b_weights <- b_rows$weight_gain
# C
c_rows <- subset(rations_df, rations_df$ration == 'C')
c_weights <- c_rows$weight_gain
# D
d_rows <- subset(rations_df, rations_df$ration == 'D')
d_weights <- d_rows$weight_gain
# Concatenate into one long vector.
all_weights <- c(a_weights, b_weights, c_weights, d_weights)
# Show the concatenated vector.
all_weights [1] 31 34 29 26 32 35 38 34 31 29 32 31 26 24 28 29 30 29 31 29 32 26 28 32 30
[26] 30 32 31 29 27 25 30 31 32 34 33 32 25 31 26 32 27 28 29 29 28 23 25n_trials <- 10000
# An vector to store the result of each trial.
results <- numeric(n_trials)
# Do 10000 trials
for (i in 1:n_trials) {
# Shuffle all the weight gains.
shuffled <- sample(all_weights)
# Split into 4 now random samples.
fake_a <- shuffled[1:12]
fake_b <- shuffled[13:24]
fake_c <- shuffled[25:36]
fake_d <- shuffled[37:48]
# Sum the weight gains for the 4 resamples.
sum_a <- sum(fake_a)
sum_b <- sum(fake_b)
sum_c <- sum(fake_c)
sum_d <- sum(fake_d)
# Find the differences between all the possible pairs of resamples.
a_b <- sum_a - sum_b
a_c <- sum_a - sum_c
a_d <- sum_a - sum_d
b_c <- sum_b - sum_c
b_d <- sum_b - sum_d
c_d <- sum_c - sum_d
# Put the differences into an vector.
fake_diffs <- c(a_b, a_c, a_d, b_c, b_d, c_d)
# Square them to give six squared differences.
sq_fake_diffs <- fake_diffs ** 2
# Sum the squares.
sum_sq_fake_diffs <- sum(sq_fake_diffs)
# Keep track of the total for each trial.
results[i] <- sum_sq_fake_diffs
# End one trial, go back and repeat until 10000 trials are complete.
}
# Produce a histogram of the trial results.
hist(results, breaks=25,
main='Null distribution of sum of squared differences',
xlab='Sum of squared differences in null world')
# Find out how many trials produced differences among groups as great as
# or greater than those observed.
k <- sum(results >= 5299)
# Convert to a proportion.
kk <- k / n_trials
# Print the result.
message('Number of sum of squared differences >= 5299: ', kk)Number of sum of squared differences >= 5299: 0.0061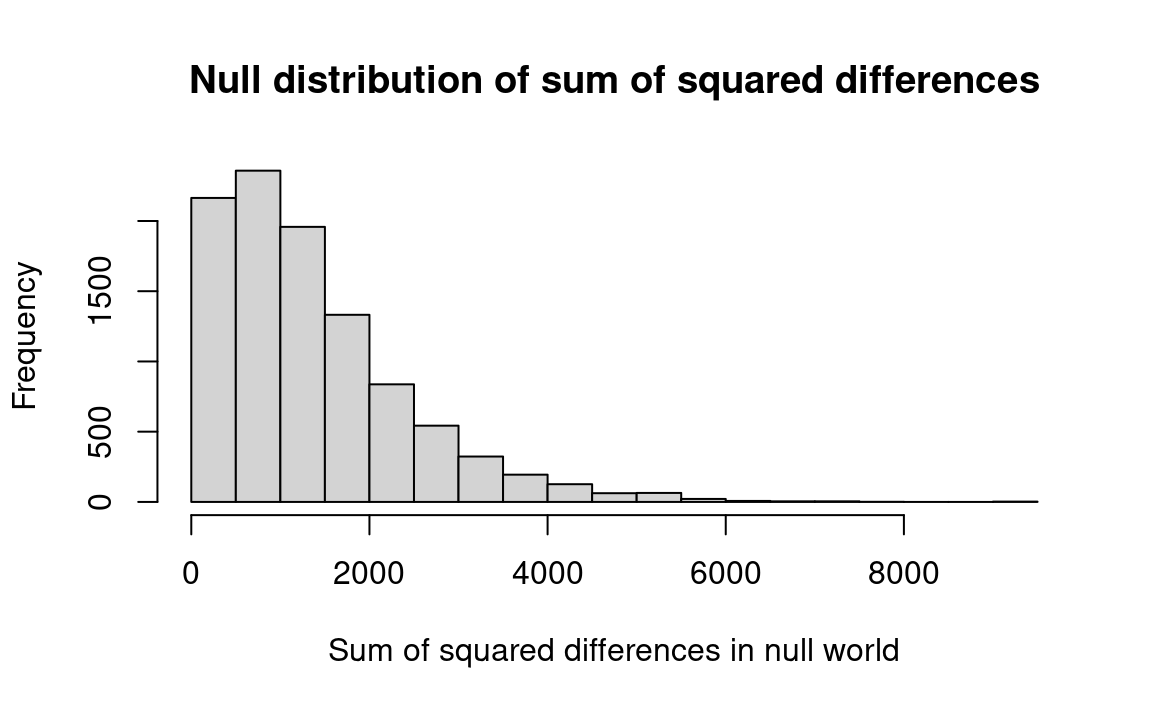
End of notebook: Sum of squared differences for pig rations
squared_rations starts at Note 24.6.
We find that our observed sum of squares — 5299 — was equaled or exceeded by randomly-drawn sums of squares in only 0.6 percent of our trials. We conclude that the four treatments are likely not all similar.
24.3 Exercises
Solutions for problems may be found in Appendix A.
24.3.1 Exercise: paired differences
The data shown in Table 24.8 might be data for the outcomes of two different mechanics, showing the length of time until the next overhaul is needed for nine pairs of similar vehicles. Or they could be two readings made by different instruments on the same sample of rock. In fact, they represent data for two successive tests for depression on a version of the Hamilton Depression Scale before and after drug therapy.6
| Patient # | Score before | Score after |
|---|---|---|
| 1 | 1.83 | 0.878 |
| 2 | 0.50 | 0.647 |
| 3 | 1.62 | 0.598 |
| 4 | 2.48 | 2.050 |
| 5 | 1.68 | 1.060 |
| 6 | 1.88 | 1.290 |
| 7 | 1.55 | 1.060 |
| 8 | 3.06 | 3.140 |
| 9 | 1.30 | 1.290 |
The task is to perform a test that will help decide whether there is a difference in the depression scores at the two visits (or the performances of the two mechanics). Perform both a bootstrap test and a permutation test, and give some reason for preferring one to the other in principle. How much do they differ in practice? (For this exercise, assume that we can treat the before and after scores as two different and independent samples and ignore the pairing between the before and after scores).
Here’s a notebook to get you started:
Note 24.7: Notebook: Paired differences exercise
df <- read.csv('data/hamilton.csv')
before <- df$score_before
after <- df$score_after
# Your code here.
End of notebook: Paired differences exercise
paired_differences starts at Note 24.7.
See Section A.1 for a solution.
24.3.2 Exercise: seatbelt proportions
Thirty-six of 72 (.5) taxis surveyed in Pittsburgh had visible seatbelts. Seventy-seven of 129 taxis in Chicago (.597) had visible seatbelts. Calculate a confidence interval for the difference in proportions, estimated at -.097. (Source: Peskun, Peter H., “A New Confidence Interval Method Based on the Normal Approximation for the Difference of Two Binomial Probabilities,” Journal of the American Statistical Association , 6/93 p. 656).
For solution, see Section A.2}
Technical Note: The test described in this section is non-parametric and therefore makes no assumptions about the shapes of the distributions, which is good because we would be on soft ground if we assumed normality in the pig-food case, given the sample sizes. This test does not, however, throw away information as do the rank and median tests illustrated earlier. And indeed, this test proves to be more powerful than the other non-parametric tests. After developing this test, I discovered that its general logic follows the tradition of the “randomization” tests, based on an idea by R.A. Fisher (1935; 1960, chap. III, section 21) and worked out for the two-sample cases by E.J.G. Pitman (1937). But the only earlier mentions of sampling from the universe of possibilities are in M. Dwass (1957) and J.H. Chung and D. Fraser (1958). I am grateful to J. Pratt for bringing the latter literature to my attention.↩︎
This short comment is the tip of the iceberg of an argument that has been going on for 200 years among statisticians. It needs much more discussion to be understandable or persuasive.↩︎
The data are from The Liquor Handbook (1962, p. 68). Eight states are omitted for various reasons. For more information, see Simon and Simon (1996).↩︎
Various tests indicate that the difference between the groups of states was highly significant. See Simon and Simon (1996).↩︎
Technical Note: Computing the sum of squared differences renders this test superficially more similar to the analysis of variance but will not alter the results. This test has not been discussed in the statistical literature, to my knowledge, except perhaps for a faint suggestion at the end of Chung and Fraser (1958). This and the two-sample test can easily be performed with canned computer programs as well as R. In addition to their advantages of nonparametricity, they are equally efficient and vastly easier to teach and to understand than the t-test and the analysis of variance. Therefore, we believe that these tests should be “treatments of choice,” as the doctors say.↩︎
The data are the contents of Hollander, Wolfe, and Chicken (2013), Table 3.1. Quoting from the description there:
The data in Table 3.1 are a portion of the data obtained by Salsburg (1970). These data, based on nine patients who received tranquilizer, were taken from a double-blind clinical trial involving two tranquilizers. The measure used was the Hamilton (1960) depression scale factor IV (the “suicidal” factor). The X (pre) was obtained at the first patient visit after initiating therapy, whereas the (post) value was obtained at the second visit after initiation of therapy.
The bibliography entry for “Salsburg (1970)” is “Personal communication (with the cooperation of Pfizer and co, Groton, Conn.)”.
We could not help but notice that Hamilton (1960) did not call his fourth factor “suicidal”, or anything else. He writes: “It is difficult to attach any label to the third and fourth factors, as they do not bring any clinical pattern to mind.”↩︎